程序从编辑到链接简介
本文只是简单介绍用GCC编译C或C++文件的基本流程,不涉及对编译和链接的深入分析
GCC 编译工具
GCC是一款强大的编译工具,下文在介绍c以及c++程序的编译运行流程中将采用gcc做示例。
GCC的初衷是为GNU操作系统专门编写的一款编译器。GNU系统是彻底的自由软件。此处,“自由”的含义是它尊重用户的自由 [2] 。
GCC 原名为 GNU C语言编译器(GNU C Compiler)
GCC(GNU Compiler Collection,GNU编译器套件)是由 GNU 开发的编程语言编
译器。GNU 编译器套件包括 C、C++、Objective-C、Java、Ada 和 Go 语言前端,也包括了这些语言的库(如 libstdc++,libgcj等)
GCC 不仅支持 C 的许多“方言”,也可以区别不同的 C 语言标准;可以使用命令行选项来控制编译器在翻译源代码时应该遵循哪个 C 标准。例如,当使用命令行参数 -std=c99 启动 GCC 时,编译器支持 C99 标准。
安装命令 sudo apt install gcc g++ (版本 > 4.8.5)
查看版本 gcc/g++ -v/--version
1.gcc 和 g++ 的关系
gcc 和 g++都是GNU(组织)的一个编译器。
后缀为 .c 的,gcc 把它当作是 C 程序,而 g++ 当作是 c++ 程序
后缀为 .cpp 的,两者都会认为是 C++ 程序,C++ 的语法规则更加严谨一些
编译阶段,g++ 会调用 gcc,对于 C++ 代码,两者是等价的,但是因为 gcc 命令不能自动和 C++ 程序使用的库联接,所以通常用 g++ 来完成链接,为了统 一起见,干脆编译/链接统统用 g++ 了,这就给人一种错觉,好像 cpp 程序只能用 g++ 似的
宏__cplusplus只是标志着编译器将会把代码按 C 还是 C++ 语法来解释,如果后缀为 .c,并且采用 gcc 编译器,则该宏就是未定义的,否则,就是已定义
编译可以用 gcc/g++,而链接可以用 g++ 或者 gcc -lstdc++
gcc 命令不能自动和C++程序使用的库联接,所以通常使用 g++ 来完成联接。 但在编译阶段,g++ 会自动调用 gcc,二者等价
2.gcc 常用编译参数
-E 预处理指定的源文件,不进行编译
-S 编译指定的源文件,但是不进行汇编
-c 编译、汇编指定的源文件,但是不进行链接
-o [file1] [file2] /[file2] -o [file1] 将文件 file2 编译成可执行文件 file1
-I directory 指定 include 包含文件的搜索目录
-g 在编译的时候,生成调试信息,该程序可以被调试器调试
-D 在程序编译的时候,指定一个宏
-w 不生成任何警告信息
-Wall 生成所有警告信息
-On n的取值范围:0~3。编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
-l 在程序编译的时候,指定使用的库
-L 指定编译的时候,搜索的库的路径。
-fPIC/fpic 生成与位置无关的代码
-shared 生成共享目标文件,通常用在建立共享库时
-std 指定C方言,如:-std=c99,gcc默认的方言是GNU C
3.GCC 工作流程
GCC工作流程也就是一个c/c++语言程序从编译到生成可执行程序的过程,如下图所示。

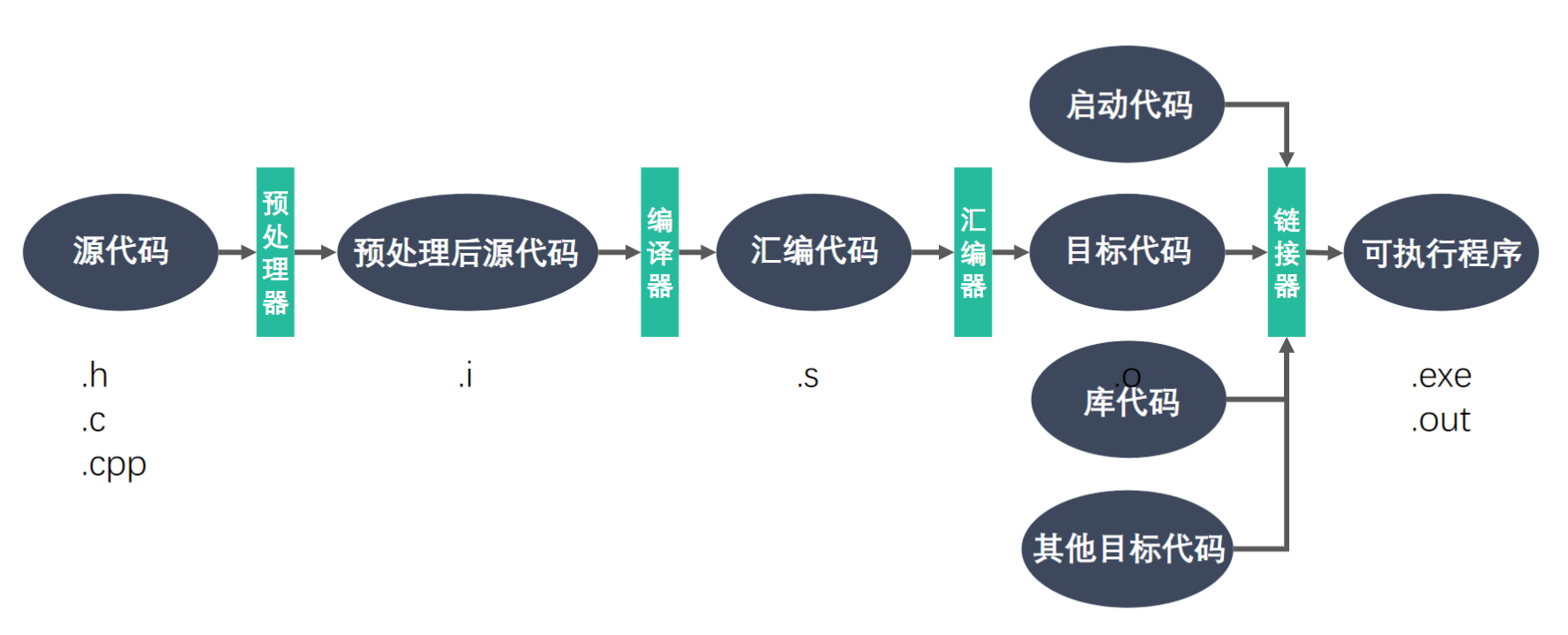

下面分别介绍各个阶段,我们的示例代码如下:
|
|
test.c
|
|
mymath.h
|
|
mymath.c
|
|
1.预处理(Preprocessing)
预处理用于将所有的#include头文件以及宏定义替换成其真正的内容,预处理之后得到的仍然是文本文件,但文件体积会大很多。
预处理器的主要作用就是: 把通过预处理的内建功能对一个资源进行等价替换,最常见的预处理有: 文件包含,条件编译、布局控制和宏替换4种。
文件包含: #include 是一种最为常见的预处理,主要是做为文件的引用组合源程序正文。
条件编译: #if,#ifndef,#ifdef,#endif,#undef等也是比较常见的预处理,主要是进行编译时进行有选择的挑选,注释掉一些指定的代码,以达到版本控制、防止对文件重复包含的功能。
布局控制: #pragma,这也是我们应用预处理的一个重要方面,主要功能是为编译程序提供非常规的控制流信息。
宏定义展开: #define,这是最常见的用法,它可以定义符号常量、函数功能、重新命名、字符串的拼接等各种功能。
gcc的预处理是预处理器cpp来完成的,你可以通过如下命令对test.c进行预处理 :
|
|
执行结果为:
|
|
看得出来经过预处理后的文件比源文件要大很多,预处理之后的程序还是文本,可以用文本编辑器打开。其内容大致如下:
|
|
2.编译(Compilation)
这里的编译不是指程序从源文件到二进制程序的全部过程,而是指将经过预处理之后的程序转换成特定汇编代码(assembly code)的过程。编译的指令如下:
|
|
上述命令中-S让编译器在编译之后停止,不进行后续过程。编译过程完成后,将生成程序的汇编代码test.s,内容如下:
|
|
3.汇编(Assemble)
汇编过程将上一步的汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件,是二进制格式。gcc汇编过程通过gcc -c命令完成:
|
|
这一步会为每一个源文件产生一个目标文件。因此mymath.c也需要产生一个mymath.o文件
|
|
4.链接(Linking)
链接过程将多个目标文件以及所需的库文件(.so等)链接成最终的可执行文件(executable file),其命令如下
|
|
目录树:
|
|
结果为:
|
|
经过以上分析,我们发现编译过程并不像想象的那么简单,而是要经过预处理、编译、汇编、链接。尽管我们平时使用gcc命令的时候没有关心中间结果,但每次程序的编译都少不了这几个步骤。也不用为上述繁琐过程而烦恼,因为你仍然可以:
|
|